
3D-LLM
Intro
Recent works have explored aligning images and videos with LLM for a new generation of multi-modal LLMs that equip LLMs with the ability to understand and reason about 2D images.
但是仍缺少对于3D物理空间进行分析的模型, which involves richer concepts such as spatial relationships, affordances, physics and interaction so on.
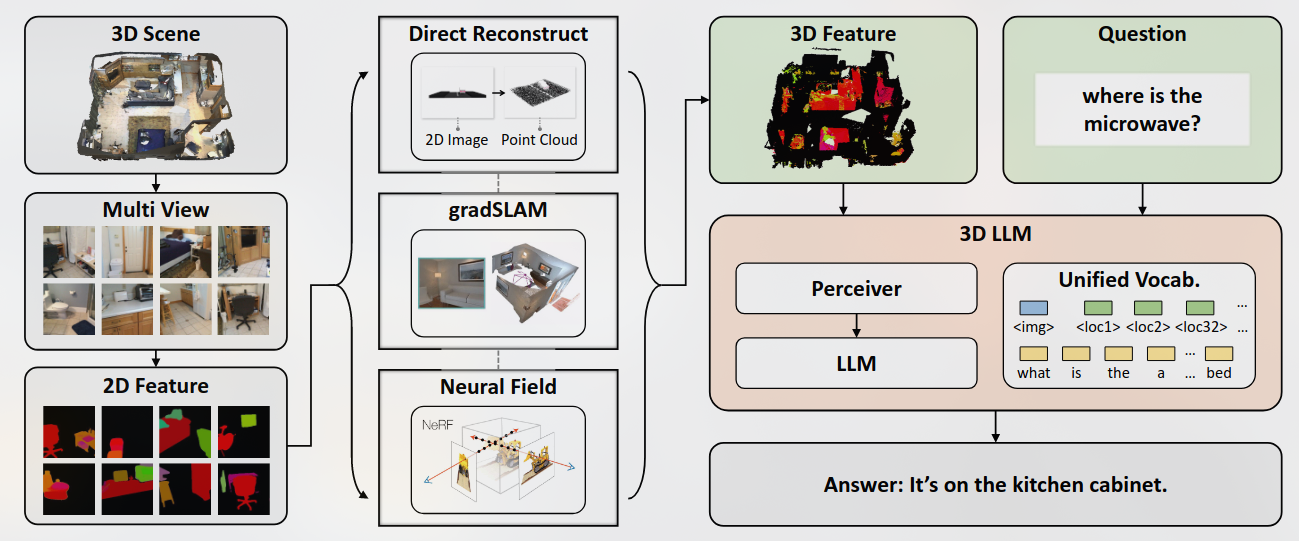
由此提出了inject the 3D world into large language models, 介绍一个全新的3D-llm模型族,可以将3D表示(即带有功能的3D点云)作为输入,并执行一系列与3D相关的任务。
优势:
- 关于整个场景的长期记忆可以存储在整体3D表示中,而不是情节的部分视图观测值
- 3D属性(如提供和空间关系)可以从3D表示形式中进行推论,远远超出了基于语言或基于2D图像的LLM的范围
挑战
- 数据获取:3D数据的稀缺性阻碍了基于3D的基础模型的发展。 3D数据与语言描述配对甚至更难获得
- 提出了一组独特的数据生成管道,这些管道可以生成大规模的3D数据与语言配对。
- Obtain meaningful 3D features that could align with language features for 3D-LLMs: 一种方法是使用类似的对比性范式从头开始训练3D编码,以在2D图像和语言之间对齐。但是,该范式消耗了巨大的数据,时间和GPU资源。
- 使用了一个3D功能提取器,该提取器构造了渲染的多视图图像的2D预处理特征的3D功能。最近,还使用了2D预训练的CLIP特征来训练其VLMS,也有很多视觉语言模型(例如Blip-2,Flamingo)。由于我们提取的3D功能与2D预处理的功能相同,因此我们可以无缝使用2D VLM作为骨架,并输入3D功能,以进行3D-LLM的有效训练。

